Real World RAG: Squint's Approach to Generative AI

Article Highlights:
- Balancing RAG Complexity: We navigate the balance between basic and hyper-optimized RAG systems, addressing the unique challenges of new tech with evolving customer needs.
- Revolutionizing Manufacturing with AI: Squint Copilot revolutionizes the manufacturing industry, offering an AI chatbot that instantly surfaces crucial operational information from customer-specific documents.
- Refining RAG for Accuracy: Through addressing query mismatches and keyword issues, we refine our RAG approach with strategies like sparse-dense vector embedding for better accuracy.
- Innovative Development and Impact: Our iterative development of Copilot demonstrates quick value delivery and highlights the potential for continuous Generative AI innovation in manufacturing
In the past year and a half, the engineering world has seen an explosion of interest in building Retrieval Augmented Generation (RAG) systems. Unfortunately, most of the advice found in the countless articles and papers on the subject doesn't touch on the practical tradeoffs and decisions faced by growing startups like Squint. There are two broad categories of content on building modern RAG: simple, bare-bones tutorials demonstrating basic implementations of the foundational RAG ideas, and complex, hyper-optimized system descriptions tailored to specific use cases that usually ignore cost and speed considerations.
Neither approach is sufficient for many products with growing customer bases and evolving use cases. Off-the-shelf RAG is unlikely to produce meaningful results and drive customer adoption, while over-optimized pipelines can paint maturing products into a corner and make iteration difficult. RAG for startups is about navigating the tradeoffs between iteration speed, future extensibility, and the reality that not all documents are created equal—RAG systems need some level of usage-specific optimization to be valuable in the real world.
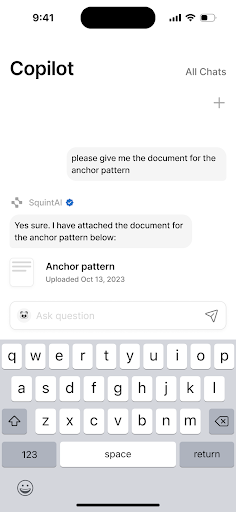
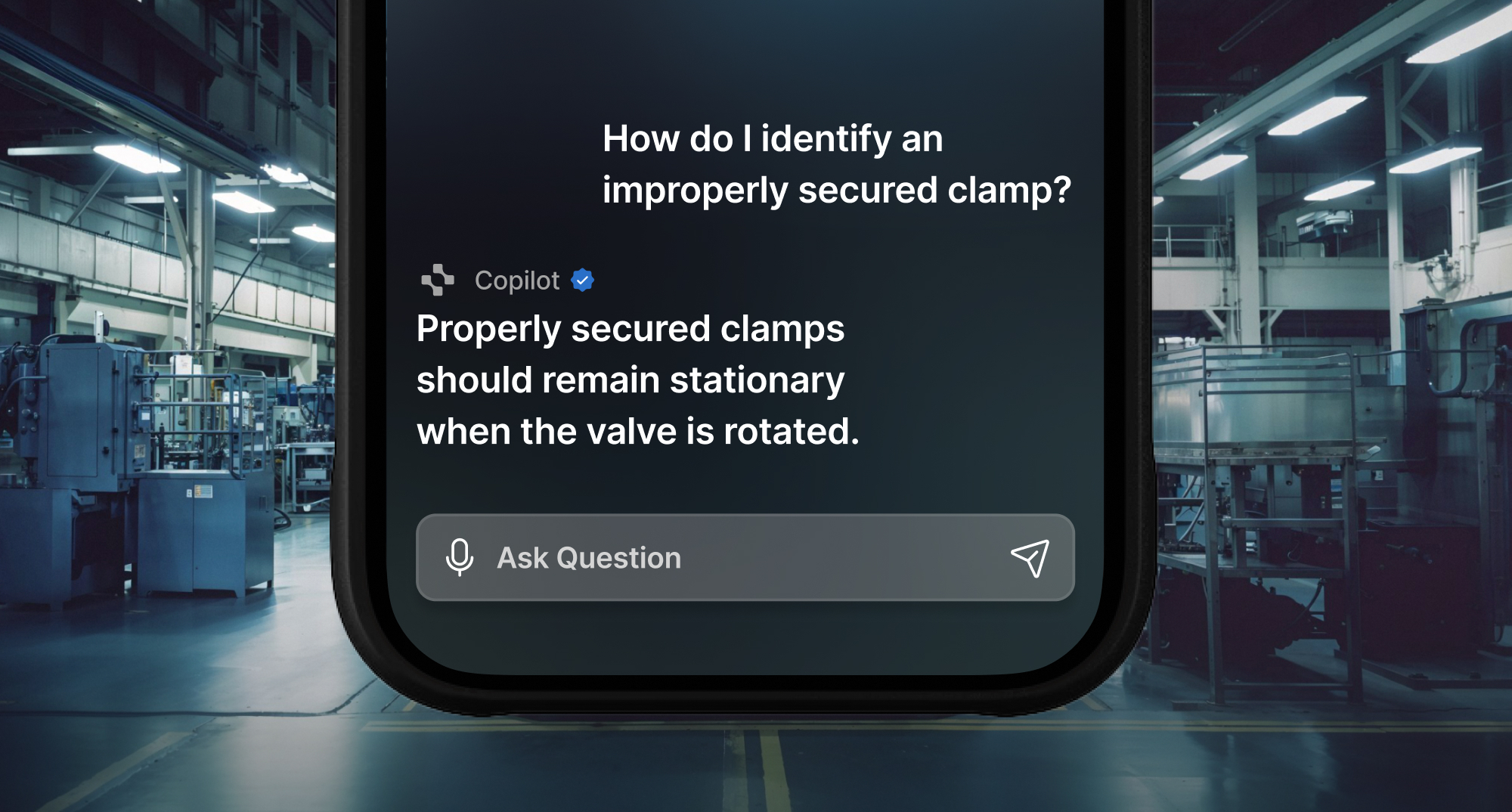
At Squint, we serve large manufacturing clients like Michelin, JTEKT, and Hershey with a best-in-class Augmented Reality app that makes training and operations radically more efficient. To further our goal of improving every facet of the manufacturing operator experience, we built Squint Copilot, a Generative AI chatbot that captures and digitizes knowledge, allowing operators to find what they need instantly. Our customers upload documents related to company policies, manufacturing Standard Operating Procedures (SOPs), and machine operation/maintenance instructions. With Squint Copilot, we aimed to provide a natural language interface that could accurately surface any information from those documents via chat. Instead of manually sifting through dozens of documents and hundreds of pages to find obscure information, operators can rely on Copilot to find answers and document sources in seconds, saving precious time on the factory floor.
We needed to ship a great product experience quickly. With the understanding that Squint Copilot would be subject to constant iteration and improvement, we proceeded under the following constraints:
- A brittle, difficult-to-change system would severely hinder future growth.
- Our customer documents are somewhat atypical compared to standard RAG examples (more on this later).
- The first version of Squint Copilot needed to provide real-world value and demonstrate the incredible power of this technology to our customers.
With those considerations in mind, here is the process we used to build our RAG pipeline:
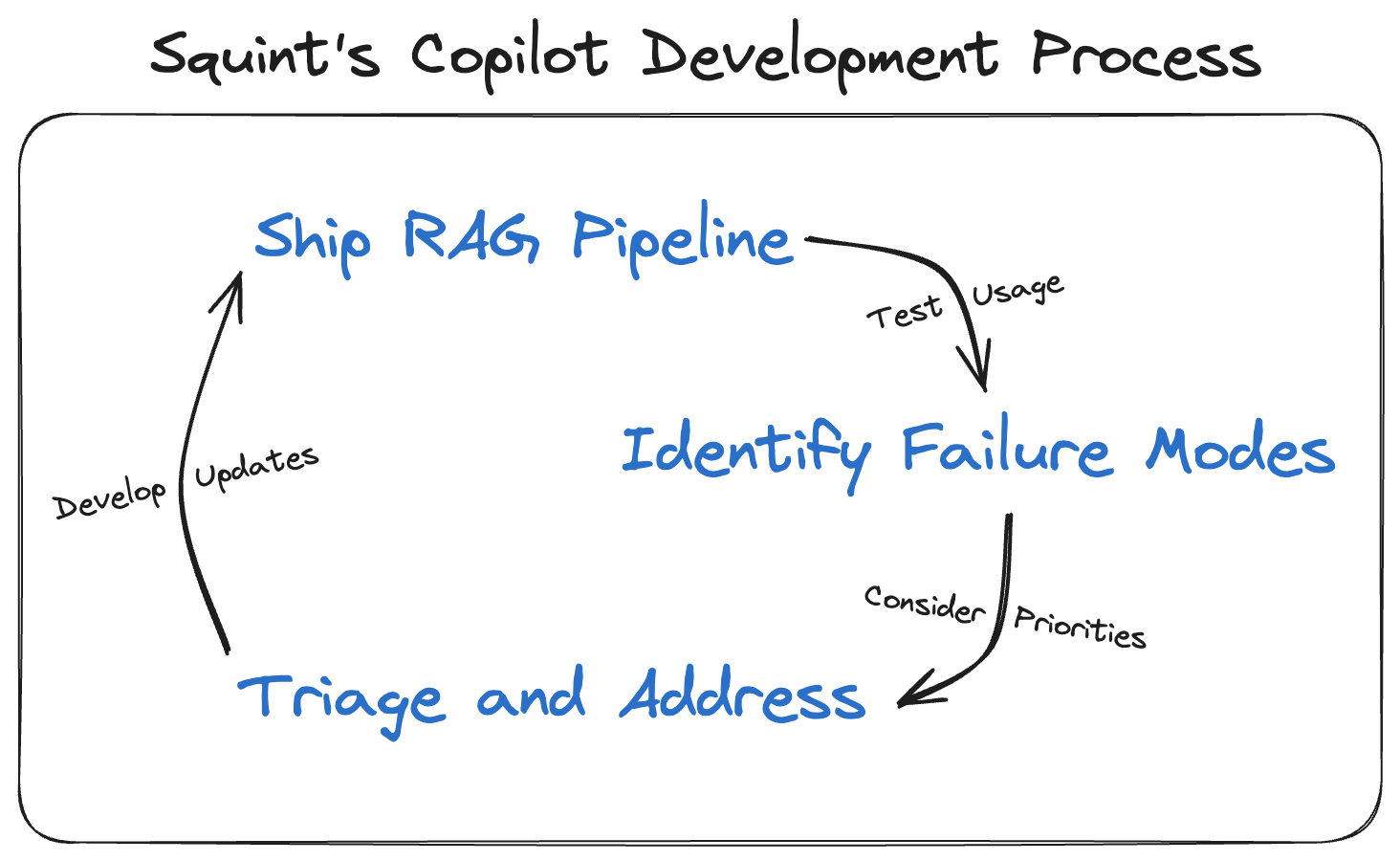
Step 1: Build the core RAG pipeline with "Off-the-Shelf" techniques
Before identifying ways to optimize our system for the manufacturing use case, we needed to validate the concept and build the foundational LLM response pipeline. Our system begins with a function triggered by a customer document upload. The function is responsible for handling document OCR, converting PDF content into raw text. The documents are then chunked into smaller pieces for vector embedding and vector db upload. After embedding, our vectors are uploaded to a vector database for later retrieval.
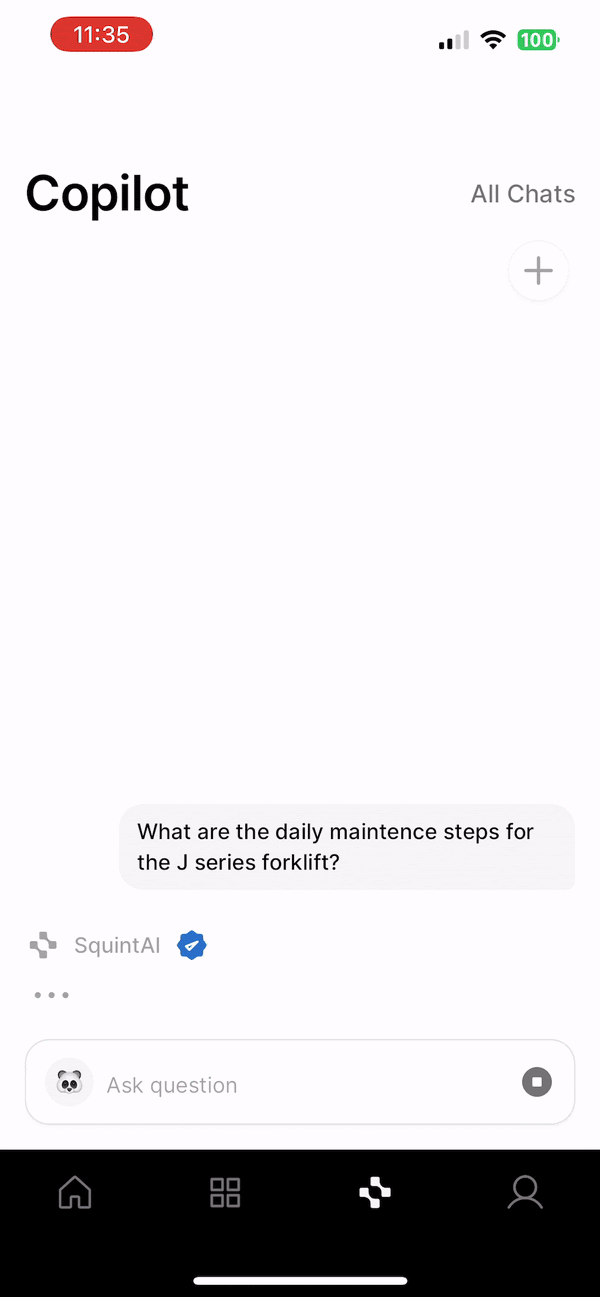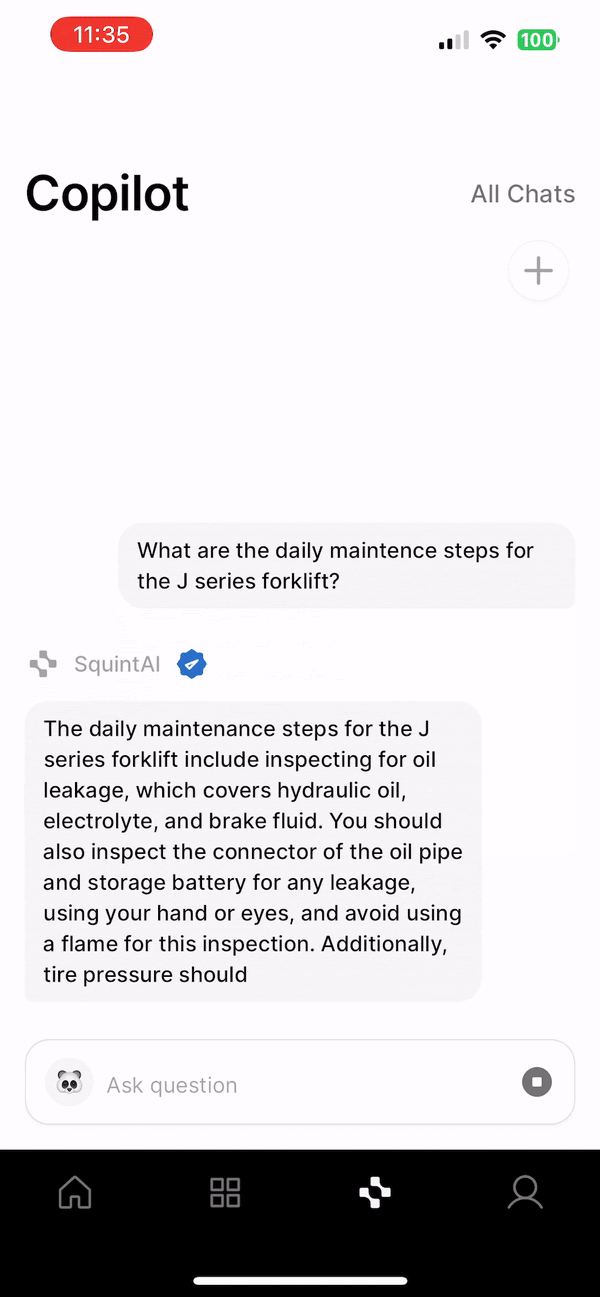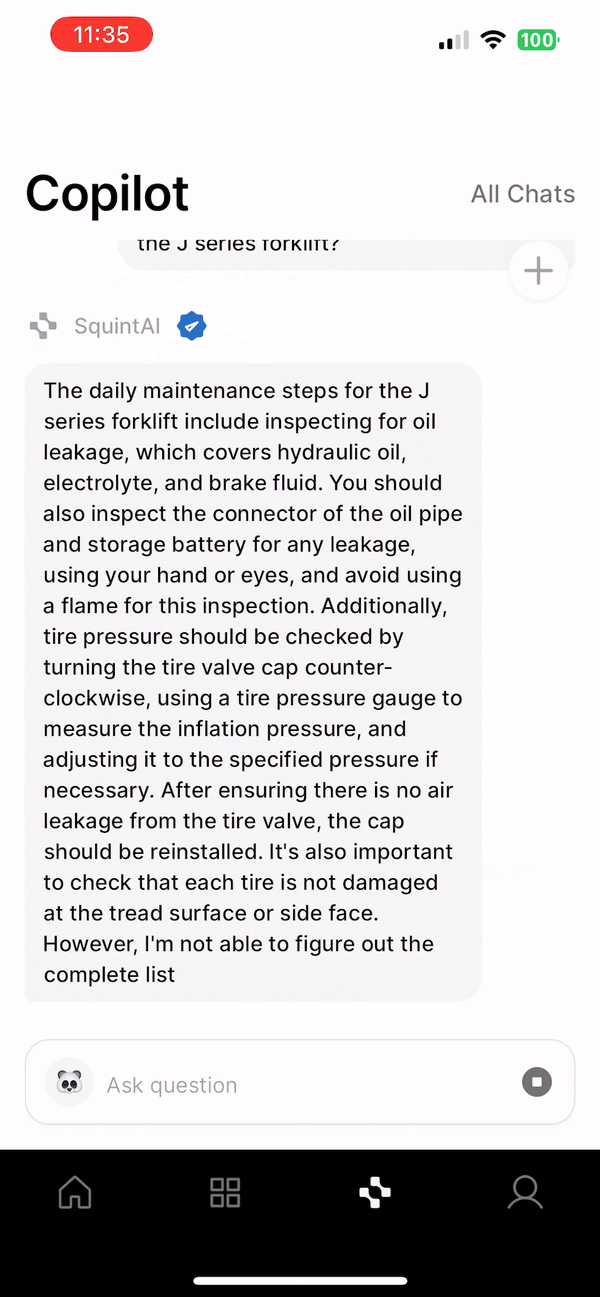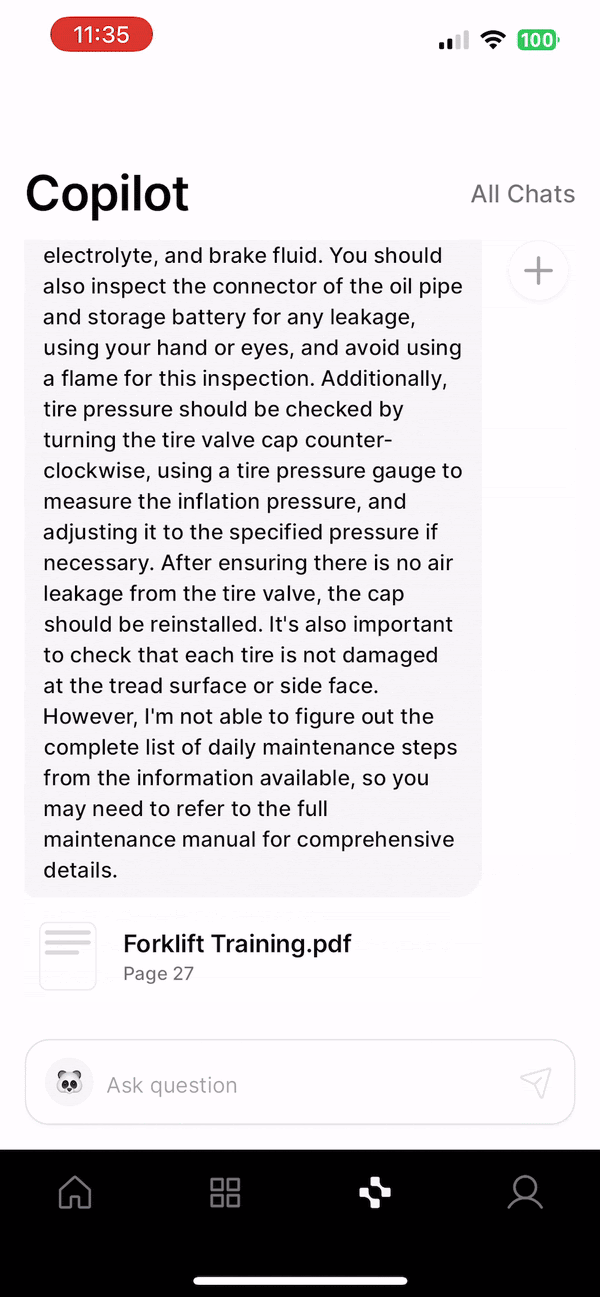
User queries begin in our mobile app, where we built a simple chat interface for operators to ask questions. Our response server would then handle a query by performing a similarity search against the vector DB to identify semantically relevant chunks. Feeding the top k chunks to an LLM prompt produced the streamed response we returned to our customers. By instructing the LLM to include its sources in a structured format, we could parse the relevant document references in the mobile client and display them to the user. Though RAG is a relatively new concept, engineering advice has converged around this basic setup to bootstrap a pipeline.
Step 2: Identify Common Failure Modes
The basic RAG setup described above produces useful results for many queries, which is a testament to the transformative power of Generative AI. However, a wide variety of queries would cause the system to miss the mark completely. Moreover, these queries tended to be the most useful for our customers—the system could handle basic queries without much issue, but deeper insights and understanding were hit or miss.
We identified three key areas in which the basic RAG pipeline was lacking. The first was general query/evidence mismatch. While the embedded query vector and relevant document chunk vectors share some semantic similarities, the differences often cause seemingly obvious chunks to be ignored by the system. Our customer documents tend not to have "straightforward" answers in their contents because of their technical nature. Answers to questions rarely appeared in the syntactic format of those questions, and abbreviations and shorthand were very common. As a result, many questions quickly answered by a human reading the document were impossible for this version of the system.
The next major failure mode was keywords. Dense vector semantic search, which powers the basic RAG setup, is largely unable to surface accurate document chunk results based on unique keywords. This is not a serious problem in many use cases, because semantic meaning alone is sufficient to identify relevant text. In our case, keyword failure was a uniquely challenging issue due to the nature of our customer documents. Because many of the documents contained proprietary machine instructions and bespoke operating processes, our chunks were littered with long strings representing part names and error codes. The meaning of these strings, which take seemingly random formats like "123XYZ44BD0" (made-up example), cannot be captured in a semantic vector space because their meaning is entirely context dependent. So, searches for queries like "How do I fix part 123XYZ44BD0" would reliably surface text chunks related to entirely different parts or produce no chunks that met our relevance threshold. These false positives and negatives would be intolerable to our customers.
Finally, like many modern RAG systems, this setup struggled with documents that contained diagrams and tables that didn't map neatly to simple text representations. Many of our customer documents relied heavily on context provided by spreadsheet-like tables and other complex formats. OCR generally fails to capture the context of these document pieces in a way that makes successful chunk matches possible.
Step 3: Triage Issues and Address Problems
We knew that optimizing our system to optimally correct for these failure modes was possible, but wanted to ensure we could ship quickly and avoid token expenses where possible. The most important problem to address was the keyword issue. We knew that customers would be somewhat understanding when the system failed to produce answers to complicated, nuanced questions, but answering questions about specific parts and instructions was such a common use case that it needed to be addressed immediately. Understanding customer psychology is key to prioritizing RAG improvements—if questions easily answerable by a human are impossible for Squint Copilot, customer trust would erode before the system had a chance to prove its merit.
We first attempted to build a second pipeline based on traditional keyword search techniques, with the idea that the two systems would merge at LLM inference time, and keyword match chunks would be included alongside dense vector chunks. In the interest of shipping speed and system extensibility, we instead opted to use a sparse-dense vector embedding strategy. When chunks are initially embedded, we added a second embedding model that computes "sparse" vector embeddings, which are high dimensional vectors containing few non-zero values. This means that dimensions roughly represent individual tokens from the document chunk, making direct keyword search possible in most cases. By adding these vectors alongside the dense vectors mentioned above, we provided a way for our query pipeline to search for both keywords and semantic meaning in the same vector database, dramatically improving responses for keyword-laden queries.
To address the query/evidence semantic mismatch issue, we implemented various LLM-based query expansion and rewriting techniques. The first of these was Hypothetical Document Embeddings (HyDE), where an LLM is instructed to invent a response to the user question. This response is then used to search against the document chunks (the idea being a hallucinated response may have semantic similarity to a real answer in the document). We also used LLMs to rephrase the question in various ways, extract keywords, and expand or simplify phrasing. By using cheaper models for these steps and performing (inexpensive!) searches against the vector database for all these rephrased queries, we expand the surface area for relevant document matches. These techniques were implemented individually and tested against a set of difficult customer questions to evaluate the extent of their performance enhancement.
We made the decision not to address the table/diagram problem in our initial feature release. As discussed earlier, production RAG is about tradeoffs—we decided that shipping a comprehensive fix to this problem would be too time-consuming for a V1. Additionally, the system manages to figure out answers to table/diagram questions more often than not, so the customer impact here was relatively low. We're already working on a fix for the next Copilot release!
Step 4: Ship, Assess, and Iterate
Squint Copilot went live in late 2023 and is already providing incredible value to operators across America. By launching more than just an MVP but less than a perfectly optimized pipeline, we were able to drive customer value quickly and begin to build up a quality dataset of queries and responses that's been critical to improving the system ahead of our next major update.
Building impactful features like Squint Copilot at high velocity has been the key to our success in transforming modern manufacturing and empowering operators. We work hard every day to continue improving every part of the product.
Thanks for reading! If you’re interested in joining our amazing team, please head over to our jobs page.